
Trong các bài trước, chúng ta đã tìm hiểu về các loại index phổ biến như Hash Index, LSM-Trees hay B-Trees, vốn được thiết kế chủ yếu cho các hệ thống OLTP (xử lý giao dịch trực tuyến). Tuy nhiên, khi chuyển sang môi trường OLAP (xử lý phân tích trực tuyến), những kỹ thuật này tỏ ra kém hiệu quả. Một giải pháp truyền thống cho OLAP là sử dụng OLAP Cube kết hợp với Materialized View, nhưng chúng vẫn tồn tại nhiều hạn chế:
Kém linh hoạt: Khi mô hình kinh doanh thay đổi, phải xây dựng lại Cube từ đầu.
Không realtime: Dữ liệu chỉ được làm mới định kỳ.
Tốn thời gian xây dựng: Với khối dữ liệu lớn, việc build Cube có thể mất hàng giờ, thậm chí hàng ngày.
May mắn thay, cùng với sự phát triển của phần cứng (bộ nhớ rẻ hơn, CPU mạnh hơn), một kiến trúc lưu trữ mới đã trở thành “chìa khóa” cho các hệ OLAP hiện đại: Column-Oriented Storage.
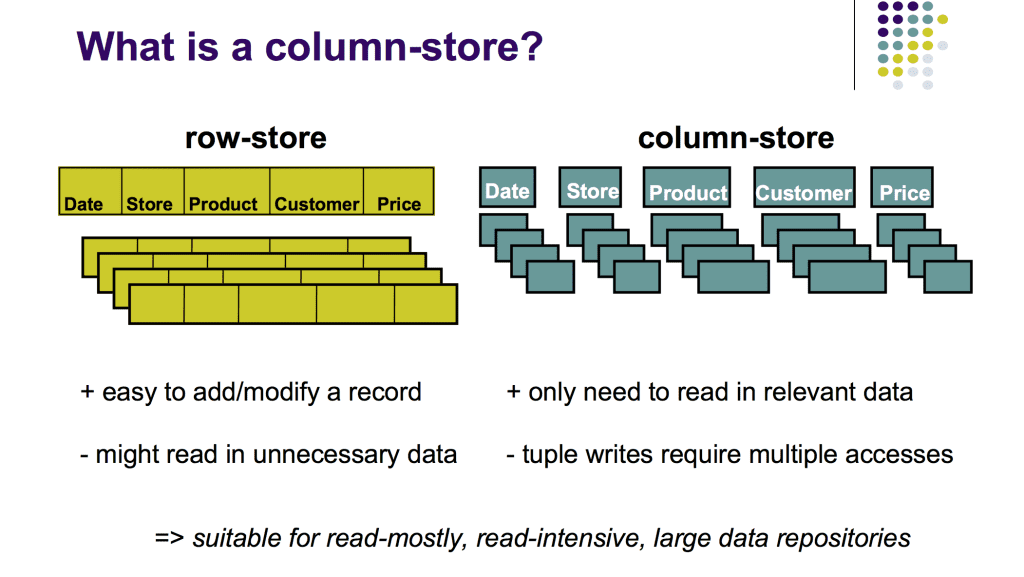
Column-Oriented Storage#
SELECT
dim_date.weekday, dim_product.category,
SUM(fact_sales.quantity) AS quantity_sold
FROM fact_sales
JOIN dim_date ON fact_sales.date_key = dim_date.date_key
JOIN dim_product ON fact_sales.product_sk = dim_product.product_sk
WHERE
dim_date.year = 2013 AND
dim_product.category IN ('Fresh fruit', 'Candy')
GROUP BY
dim_date.weekday, dim_product.category;
Thay vì lưu dữ liệu theo từng dòng (row) như truyền thống, Column-Oriented Storage lưu từng cột (column) thành các khối dữ liệu riêng biệt. Các giá trị trong cùng một cột được lưu liên tiếp nhau, và thứ tự của chúng được giữ nguyên so với thứ tự dòng gốc.
Ví dụ với bảng fact_sales:

Tại sao lại phù hợp cho OLAP?#
Mặc dù bảng Fact thường có thể lên tới hàng trăm cột, tuy nhiên lúc thống kê ta lại chỉ cần dùng tới 3-4 cột trong số chúng. Ví dụ như này:
SELECT
dim_date.weekday, dim_product.category,
SUM(fact_sales.quantity) AS quantity_sold
FROM fact_sales
JOIN dim_date ON fact_sales.date_key = dim_date.date_key
JOIN dim_product ON fact_sales.product_sk = dim_product.product_sk
WHERE
dim_date.year = 2013 AND
dim_product.category IN ('Fresh fruit', 'Candy')
GROUP BY
dim_date.weekday, dim_product.category;
Với Row-Oriented Storage, hệ thống phải đọc toàn bộ các dòng (gồm tất cả cột) rồi mới lọc ra những cột cần thiết. Trong khi đó, Column-Oriented Storage chỉ cần đọc đúng các cột date_key, product_sk và quantity, giảm đáng kể lượng I/O và tăng tốc truy vấn.
Nén dữ liệu – Bitmap Encoding#
Một lợi thế lớn của lưu trữ hướng cột là khả năng nén dữ liệu cao. Một kỹ thuật phổ biến là Bitmap Encoding – mã hóa dưới dạng sparse vector (vector thưa):

Với mỗi giá trị duy nhất, ta tạo một vector bitmap độ dài N (số bản ghi), trong đó bit = 1 nếu dòng đó chứa giá trị đó. Khi số lượng giá trị duy nhất ít nhưng số dòng (N) rất lớn, bitmap thường rất thưa (nhiều số 0). Ta có thể nén tiếp bằng Run-Length Encoding (RLE).
Ví dụ với product_sk = 69:
Bitmap:
1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 1 1RLE:
0,4,12,2(0 số 0, 4 số 1, 12 số 0, 2 số 1)
Truy vấn trực tiếp trên dữ liệu nén#
Bitmap cho phép thực hiện nhiều phép toán trực tiếp mà không cần giải nén:
WHERE product_sk IN (30, 68, 69):
Load bitmap của 3 giá trịproduct_sk = 30,product_sk = 68, vàproduct_sk = 69, rồi thực hiện phép toán OR trên 3 cái bitmap đó → Thu được vector trong đó các vị trí có số 1 chính là vị trí thứ tự của bản ghi thỏa mãn.WHERE product_sk = 31 AND store_sk = 3:
Load bitmap của giá trịproduct_sk = 31vàstore_sk = 3, rồi thực hiện phép toán AND trên chúng. Nhờ vào việc “Thứ tự của các giá trị trong column trùng khớp với thứ tự của row” → Thu được vector trong đó các vị trí có số 1 chính là vị trí thứ tự của bản ghi thỏa mãn.
Nhờ vậy, truy vấn vừa nhanh vừa tiết kiệm bộ nhớ.
Các thuật toán nén phổ biến#
Ngoài ra, còn nhiều cách mã hóa khác nhau tương ứng với từng kiểu data, ta sẽ không đi sâu thêm vào chi tiết phần đó. Có gì nếu quan tâm kĩ hơn thì các bạn tham khảo thêm ở đây. Dưới đây mình xin liệt kê 1 số kiểu phổ biến:
Run-Length Encoding (RLE)
Phù hợp: Dữ liệu có nhiều giá trị lặp lại liên tiếp
Ví dụ:
[1,1,1,1,2,2,2,3,3]→(1,4), (2,3), (3,2)Ứng dụng: Date columns, status flags, low-cardinality columns
Delta Encoding
Phù hợp: Dữ liệu số có thứ tự (timestamps, sequence IDs)
Ví dụ:
[1000, 1002, 1005, 1008]→[1000, 2, 3, 3]Ưu điểm: Giảm kích thước khi giá trị tăng đều
Dictionary Encoding
Phù hợp: Cột có ít giá trị duy nhất (low cardinality)
Ví dụ:
["US", "UK", "US", "FR", "UK"]→ Dictionary:{"US":0, "UK":1, "FR":2}, Data:[0,1,0,2,1]
XOR Compression (Gorilla Encoding)
Phù hợp: Time-series data với giá trị thay đổi chậm
Nguyên lý: Lưu XOR giữa giá trị hiện tại và trước đó
Ví dụ:
10.5, 10.6, 10.9→10.5, (0.1), (0.3)
LZ77/LZ78 (Lempel-Ziv)
Phù hợp: Văn bản có cụm từ lặp lại
Biến thể: DEFLATE (gzip), LZ4, Snappy
Ứng dụng: Nén toàn bộ cột dạng binary
Bit-packing
Phù hợp: Số nguyên nhỏ trong khoảng [0, N]
Ví dụ: Số từ 0-15 → chỉ cần 4 bit thay vì 8 bit
Ứng dụng: Dictionary indices
Lựa chọn thuật toán dựa trên đặc điểm dữ liệu#
High cardinality + Unsorted → Dictionary + Bit-packing
Low cardinality → Dictionary hoặc RLE
Sorted + Sequential → Delta encoding hoặc RLE
Floating-point time-series → Gorilla encoding
Text with repetition → LZ variants
Sparse data → Bitmap với RLE nén
Sự lựa chọn của các hệ thống tiêu biểu#
| Thuật toán | Kiểu dữ liệu | Điểm mạnh | Hệ thống sử dụng |
| Zstandard | Tất cả (general) | Tốc độ nén/giải nén cao | Parquet, ORC |
| LZ4 | Tất cả | Giải nén cực nhanh | ClickHouse, Druid |
| Brotli | Văn bản | Tỉ lệ nén cao | Web compression, BigQuery |
| ZigZag | Số nguyên có dấu | Hiệu quả với số nhỏ | Protocol Buffers, Avro |
| Patched Frame of Reference | Số nguyên | Tự động chọn block size | Apache Arrow |
Ghi dữ liệu trong Column-Oriented Storage#
Chúng ta không thể dùng cơ chế cập nhật tại chỗ (in-place update) như B-Tree vì việc chèn/xóa một dòng sẽ ảnh hưởng đến toàn bộ các cột. Thay vào đó, có thể áp dụng mô hình LSM-Tree:
Dữ liệu ghi mới được lưu tạm trong bộ nhớ (memtable) và sắp xếp theo thứ tự tối ưu cho thuật toán nén sau này.
Khi memtable đủ lớn, dữ liệu được ghi xuống disk với cấu trúc nén Column-oriented.
Định kỳ sẽ có tiến trình compaction xử lý merge những file trong disk lại.
Truy vấn đọc từ cả memtable và các file trên đĩa, rồi sau đó kết hợp cả 2 lại.
Kết luận#
Column-Oriented Storage không chỉ giúp giảm I/O bằng cách chỉ đọc những cột cần thiết, mà còn tận dụng nhiều kỹ thuật nén (bitmap, RLE, dictionary encoding, v.v.) để tiết kiệm không gian lưu trữ và tăng tốc xử lý truy vấn phân tích. Cùng với cơ chế ghi kiểu LSM-Tree, nó trở thành nền tảng cho nhiều hệ cơ sở dữ liệu OLAP hiện đại như Amazon Redshift, Google BigQuery, và ClickHouse.
Hy vọng qua bài viết này, bạn đã có cái nhìn rõ ràng hơn về Column-Oriented Storage và tại sao nó lại phù hợp cho các tác vụ phân tích dữ liệu lớn.